
Pentaho
Iniciando Aplicativo
Navegue até o diretório que foi descompactado o programa e procure o arquivo Spoon.bat.
Kettle é um acrônimo para “Kettle E.T.T.L. Environment.“. O Kettle foi projetado para ajudar no ETTL (Extraction, Transformation, Transportation and Loading of data). Spoon é uma interface gráfica que permite projetar transformações e trabalhos que podem ser executados com a ferramenta Kettle.
Pan e kitchen.
Pan é o motor das transformações dos dados ele realiza uma série de funções, tais como leitura, manipulação e gravação dos dados.
Kitchen executa trabalhos realizados no spoon em XML ou no repositório de banco de dados. Os trabalhos são normalmente programadas no modo batch para ser executado automaticamente no período agendado.

Criando uma Transformação
Existem três maneiras de iniciar uma transformação no Pentaho Data Integration.
- Clique em File – Novo – Transformação
- Pressione Ctrl + N
- Clique na figura que parece uma folha (abaixo de File) e escolha “Transformation“.


Conexão com a Base de Dados
O PDI é uma ferramenta bastante versátil com relação a conexão com outras bases de dados, já trabalhei com diversas fontes de dados dentre elas posso citar: – Oracle – Postgre – Sql Server (Versões 2000 – 2005 e 2008).
Bom como estamos realizando teste com a base do Oracle, então vou disponibilizar o “jar” que vai estabelecer a conexão da ferramenta com o banco de dados. Então vamos lá, o driver de conexão do Oracle é “ojdbc14.jar“, você tem que salvar esse arquivo na pasta “data-integration\libext\JDBC”
Download do Jar para conexão com o Oracle ****Java Archive (JAR) é um arquivo compactado usado para distribuir um conjunto de classes Java, um aplicativo java, ou outros itens como imagens, XMLs, entre outros.
É usado para armazenar classes compiladas e metadados associados que podem constituir um programa. (http://pt.wikipedia.org/wiki/Java_Archive)
Criando uma Conexão com o Banco de Dados
Para criar uma nova conexão com o Banco de Dados, existe três possibilidades para adicionar uma nova conexão.
- Clique duas vezes com o botão direito do mouse sobre “Conexões“.
- Clique com o Botão esquerdo do mouse e escolha “Novo“.
- Pressione a tecla “F3” e abrirá a janela com o assistente do banco.
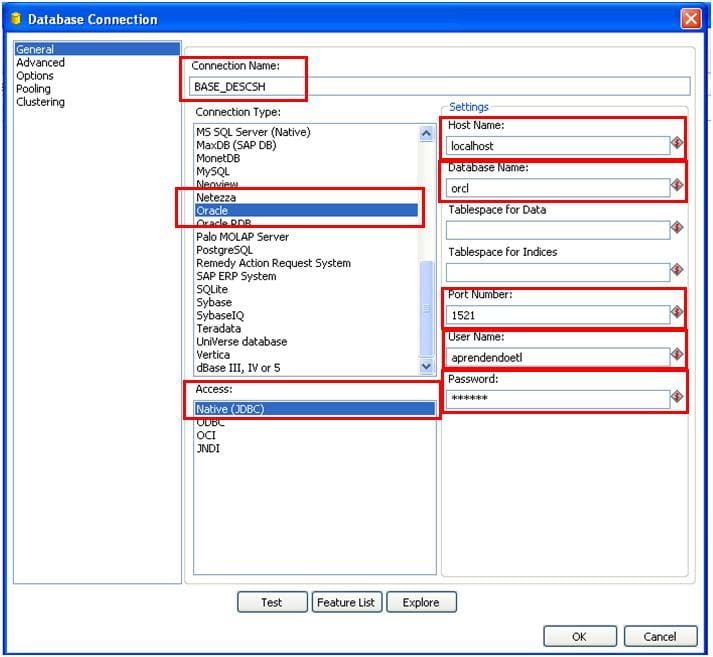
Parâmetros de configuração do Banco de Dados
Nessa etapa vamos configurar o acesso ao banco de dados, para isso vamos precisar das informações de acesso ao banco de dados. Como trabalho com o banco de dados Oracle, vou configurar das informações do host, Nome da base de Dados, Número da Porta, Usuário e senha.
- Host Name Coloque o ip da máquina que você deseja conectar, no meu exemplo estou acessando remotamente a minha máquina.
- Database Name Coloque o sid da conexão com o banco de dados, caso esteja em dúvida procure o DBA da sua empresa.
- Port Number Geralmente a porta de conexão com o oracle é a 1521, porém fica a critério do DBA a escolha da porta.
- User Name O usuário do banco de dados.
- Password Coloque a senha de acesso ao banco de Dados.
- Connection Name Atribua um nome para sua conexão.
Faça um teste, para verificar se tudo está correto.
Design Steps
Vou resumir de modo superficial os steps do Spoon, são centenas de opções para o analista realizar suas transformações nessa poderosa ferramenta, dependendo de sua necessidade é possível chegar no resultado esperado. Big Data Big data se trata de um conceito, no qual o foco é o grande armazenamento de dados e maior velocidade. A pentaho já prevendo o futuro disponibiliza na sua ferramenta integração com as tecnologias:
- Apache Cassandra é um projeto de sistema de banco de dados distribuído altamente escalável de segunda geração, que reúne a arquitetura do Dynamo, da Amazon e modelo de dados baseado no BigTable, do Google. O Cassandra inicialmente foi criado pelo Facebook, que abriu seu código-fonte para a comunidade em 2008. (http://en.wikipedia.org/wiki/Apache_Cassandra).
- Hadoop é uma ferramenta open source que suporta o uso intensivo de dados e aplicações distribuídas. Hadoop foi criado por Doug Cutting e J. Michael Cafarella que trabalhando na época no Yahoo.
- HBase é uma ferramenta open source, não relacional, banco de dados distribuído após Google s BigTable escrito em Java. Apache HBase iniciou com um projeto da empresa Powerset, após a necessidade de processar grandes quantidades de dados para fins de pesquisa de linguagem natural.
- MongoDb é uma ferramenta open source, document-oriented database(Um programa projetado para armazenamento, recuperação e gerencimento orientado a documentos ) e desenvolvido pela empresa 10gen.
As tecnologias que sustentam Big Data podem ser analisadas sob duas óticas: as envolvidas com analytics, tendo Hadoop e MapReduce como nomes principais e as tecnologias de infraestrutura, que armazenam e processam os petabytes de dados.
Neste aspecto, destacam-se os bancos de dados NoSQL (No, significa not only SQL). Por que estas tecnologias? Por que Big Data é a simples constatação prática que o imenso volume de dados gerados a cada dia excede a capacidade das tecnologias atuais de os tratarem adequadamente.
Input Step responsável por realizar a entrada dos dados no processo de ETLCSV file input Step fornece a capacidade de lê dados de um arquivo delimitado.
- Data Grid Permite que você digite uma lista estática de linhas em uma grid. Geralmente é utilizada para fins de referência, teste ou demonstrações.
- De-serialize from file Antes conhecido como Cubo de Entrada lê linha de dados de um arquivo binário conténdo linhas e metadados.
- Email messages input Lê e recupera mensagens do servidor POP3/IMAP.
- ESRI Shapefile Reader ou simplesmente shapefile é um formato popular de arquivo conténdo dados geoespaciais em forma de vetor usado por Geographic Information System (Sistemas de Informações Geográficas) também conhecidos como GIS. Foi desenvolvido e regulamentado por Esri como um especificação aberta para interoperabilidade por dados entre os softwares de Esri e de outros fornecedores.
- Fixed File Input Este Step é utilizado para leitura de dados com largura fixa.
- Generate random credit card numbers Este Step gera número de cartões de crédito aleatórios com a verificação do algoritmo Luhn.
- Generate Random Value Este Step gera números aleatórios, inteiros, String e UUID (Universally Unique Identifier).
- Generate Rows Este Step gera um número de linhas, por padrão as linhas estão vazias, porém podem conter um número de campos estáticos.
- Get Data From XML Este Step fornece a capacidade de lê dados de qualquer arquivo do tipo XML de acordo com as especificações XPath.
- Get File Names Este Step permite que você obtenha informações associadas com nomes do arquivo do sistema.
- Get Files Rows Count Este Step conta o número de linha do arquivo ou do conjunto de arquivos.
- Get repository names Este Step lista informações detalhadas sobre as transformações ou Jobs no repositório.
- Get SubFolder names Este Step lê uma pasta pai e retorna todas as subpastas vinculadas a ela.
- Get System Info Este Step recupera informações do ambiente Kettle.
- Get table names Este Step lista nome de tabelas do banco de dados e envia para o próximo Step.
- Google Analytics Este Step obtém dados da conta do google analytics, para gerar relatórios ou popular seu data warehouse.
- GZIP CSV Input Este Step lê arquivo compactado no programa GZIP (abreviação de GNU zip, um Software Livre de compressão sem perda de dados).
- HL7 Input Este Step fornece a capacidade de lê dados a partir de fluxo de dados dentro de uma transformação HL7. (Health Level 7 é um padrão ANSI, que é usado para padronização da linguagem médica.)
- Json Input Este Step extrai partes relevantes da estrutura Json (JavaScript Object Notation), é um formato leve para intercâmbio de dados computacionais.
- LDAP Input Este Step lê informações de usuários, regras e outros dados do servidor LDAP (Lightweight Directory Access Protocol).
- LDIF Input Este Step lê dados de arquivo LDIF (LDAP Data Interchange Format ).
- Load file content in memory Este Step carrega o conteúdo do arquivo na memória.
- Microsoft Access Input Este Step lê dados do Access diretamente dos arquivos (MDB).
- Microsoft Excel Input Este Step lê informações de um ou mais arquivos do Excel ou OpenOffice.
- Mondrian Input Este Step lê dados de uma base de dados utilizando a descrição do esquema do Mondrian (catálogo) e uma consulta MDX . Mondrian é uma ferramenta de OLAP(Processamento Analítico Online) de código aberto.
- OLAP Input Este Step lê informações de uma fonte de dados XML/A (XML for Analysis), que é um padrão para acesso a dados de sistemas de análise, tais como OLAP e Data Mining.
- Property Input Este Step lê arquivos de propriedade Java. O .properties é uma extensão de arquivos utilizados em Java relacionando tecnologia para armazenamento e parâmetros da configuração da aplicação.
- RSS Input Este Step lê informações de RSS (Rich Site Summary). RSS é um subconjunto de dialetos XML que servem para agregar conteúdo ou Web syndication , podendo ser acessado mediante programas ou sites agregadores. É usado principalmente em sites de notícias e blogs.
- S3 CSV Input Este Step lê informações do serviço da Amazon Web Services (AWS), que é um conjunto de serviços de computação remota (também chamados web services) que juntos, constituem uma plataforma de computação em nuvem, proporcionada através da Internet pela Amazon.com. Os serviços mais populares são o Amazon EC2 e o Amazon S3.
- Salesforce Input Este Step fornece a capacidade de lê dados diretamente do SalesForce usando o SalesForce Web Services. Salesforce é uma empresa americana de software on demand (software a pedido), mais conhecida por ter produzido o CRM com o mesmo nome da empresa.
- SAP Input Este Step chama funções do Sistema SAP e carrega tabelas na função RFC_READ_TABLE ou personalizada.
- Table Input Este Step lê informações de tabelas do Banco de Dados. É o Step que mais utilizo no meu processo de ETL.
- Text file Input Este Step lê informações de arquivos texto.
- XBase Input Este Step lê registros de um tipo de banco de dados, arquivos do tipo (DBF). exemplo: – dBase III/IV, – Foxpro, – Clipper e outros;
- XML Input Stream (StAX) Este Step é capaz de processar grandes e complexos arquivos XML rapidamente.
- Yaml Input Este Step lê fontes (arquivos ou Stream) analisa e converte em linhas e escreve em um ou mais saídas.
Output Step responsável pela saída dos dados no processo de ETL
- Automatic Documentation Output Este Sptep gera automaticamente uma documentação baseada na entrada e forma uma lista de transformações. Ele suporta apenas transformações e jobs.
- Delete Este Step deleta registros da tabela do Banco de Dados utilizando um campo chave.
- Insert / Update Este Step é uma mão na roda, insere ou atualiza registros novos nas tabelas do Banco de Dados.
- Json output Este Step cria blocos Json e gera um campo ou arquivo.
- LDAP output Este Step executa Insert, upsert, update, adiciona ou deleta operações no registros baseado no seu DN (Distinguished Name).